【耳コピ】音楽ファイルを楽器ごとに分離する方法【Spleeter:フリー】
今回は、mp3 などの音楽ファイルをボーカル、ベース、ドラムなどの楽器ごとに分離してそれぞれのファイルに出力する方法について紹介します。
「Spleeter」というディープラーニングを使ったツールなのですが、精度も良く、しかも無料で使えるため、耳コピをしたりとかカラオケ音源を作りたい場合におすすめです。
Python というプログラミング言語で書かれたスクリプトを実行しないといけないため、初心者の方は多少抵抗があるかもしれませんが、以下の手順で割と簡単に実行できました。
パソコンの OS の環境は、Windows 10 で行いました。
Contents
Anaconda のインストール
まず、Python を実行できる環境を作ります。
そのために、Anaconda をインストールします。
以下のサイトからインストールしてください。
ライブラリのインストール
次に、「Spleeter」を実行するために必要なライブラリ群をインストールします。
yaml ファイルを作って、一括でライブラリをインストールします。
以下の内容をコピペして、「spleeter-cpu.yaml」という名前で保存します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
name: spleeter-cpu channels: - conda-forge - anaconda dependencies: - python=3.7 - tensorflow=1.14.0 - ffmpeg - pandas==0.25.1 - requests - pip - pip: - museval==0.3.0 - musdb==0.3.1 - norbert==0.2.1 - spleeter |
次に、デスクトップにある「Anaconda Prompt」を 実行し、「spleeter-cpu.yaml」ファイルがあるフォルダまで、「cd」コマンドで移動します。
コマンドプロンプト上で、以下を実行します。
|
1 |
> conda env create -f spleeter-cpu.yaml |
以下のようなメッセージが出力されればライブラリのインストールが完了です。
|
1 2 3 4 5 6 7 8 9 10 11 |
Successfully installed PyYAML-5.4.1 anyio-3.3.1 appdirs-1.4.4 astunparse-1.6.3 attrs-21.2.0 audioread-2.1.9 cached-property-1.5.2 cachetools-4.2.2 click-7.1.2 colorama-0.4.4 decorator-5.1.0 ffmpeg-python-0.2.0 flatbuffers-1.12 future-0.18.2 gast-0.4.0 google-auth-1.35.0 google-auth-oauthlib-0.4.6 grpcio-1.34.1 h11-0.12.0 h2-4.0.0 h5py-3.1.0 hpack-4.0.0 httpcore-0.13.7 httpx-0.19.0 hyperframe-6.0.1 importlib-metadata-3.10.1 joblib-1.0.1 jsonschema-3.2.0 keras-nightly-2.5.0.dev2021032900 librosa-0.8.0 llvmlite-0.36.0 musdb-0.3.1 museval-0.3.0 norbert-0.2.1 numba-0.53.1 numpy-1.19.5 oauthlib-3.1.1 opt-einsum-3.3.0 packaging-21.0 pandas-1.3.3 pooch-1.5.1 pyaml-21.8.3 pyasn1-0.4.8 pyasn1-modules-0.2.8 pyparsing-2.4.7 pyrsistent-0.18.0 requests-oauthlib-1.3.0 resampy-0.2.2 rfc3986-1.5.0 rsa-4.7.2 scikit-learn-1.0 simplejson-3.17.5 six-1.15.0 sniffio-1.2.0 soundfile-0.10.3.post1 spleeter-2.3.0 stempeg-0.2.3 tensorboard-2.6.0 tensorboard-data-server-0.6.1 tensorboard-plugin-wit-1.8.0 tensorflow-2.5.0 tensorflow-estimator-2.5.0 threadpoolctl-2.2.0 tqdm-4.62.3 typer-0.3.2 typing-extensions-3.7.4.3 done # # To activate this environment, use # # $ conda activate spleeter-cpu # # To deactivate an active environment, use # # $ conda deactivate |
以下のコマンドで、「spleeter-cpu」が表示されることを確認します。
|
1 |
> conda info --envs |
|
1 2 3 4 |
# conda environments: # base * C:\Users\XXXX\anaconda3 spleeter-cpu C:\Users\XXXX\anaconda3\envs\spleeter-cpu |
Spleeter を実行
まず、以下のコマンドで「spleeter-cpu」を有効にします。
|
1 |
> conda activate spleeter-cpu |
次に、以下のコマンドで、分離させる音楽ファイルなどを指定させます。
|
1 |
(spleeter-cpu) C:\Users\XXXX\Music\spleeter-cpu>spleeter separate konomatide-kimito-kurashitai.mp3 -o . -p spleeter:4stems |
「konomatide-kimito-kurashitai.mp3」部分が音楽ファイルになります。
ちなみに、ファイル名が日本語の場合は「”英雄.mp3″」のように ” ” を使います。
また、「spleeter:4stems」とすると、
- ボーカル(vocal)
- ドラム(drums)
- ベース(bass)
- その他
に分離され、それぞれ「wav」ファイルが出力されます。
出力結果は、以下のようになります。
|
1 2 3 4 5 6 7 8 |
INFO:spleeter:Downloading model archive https://github.com/deezer/spleeter/releases/download/v1.4.0/4stems.tar.gz INFO:spleeter:Validating archive checksum INFO:spleeter:Extracting downloaded 4stems archive INFO:spleeter:4stems model file(s) extracted INFO:spleeter:File .\konomatide-kimito-kurashitai/vocals.wav written succesfully INFO:spleeter:File .\konomatide-kimito-kurashitai/drums.wav written succesfully INFO:spleeter:File .\konomatide-kimito-kurashitai/bass.wav written succesfully INFO:spleeter:File .\konomatide-kimito-kurashitai/other.wav written succesfully |
入力音楽ファイルと同じ名前のフォルダが作成され、wavファイルが出力されていることが確認できました。
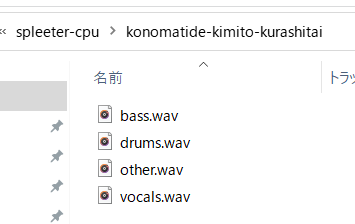
1曲だと実行時間もそこまでかからず、分離精度もかなりいい感じでした!
関連記事
記事はありませんでした