【PyTorch】畳込みニューラルネットワークを構築する方法【CNN】
今回は、PyTorch を使って畳込みニューラルネットワーク(CNN)を構築する方法について紹介します。
PyTorch でニューラルネットワーク(NN)を構築する方法については以前まとめたので、よかったら参考にしてみてください。
【PyTorch】ニューラルネットワークを構築する方法【NN】
手順はニューラルネットと同様なので、主に異なる点についてまとめてみます。
動作環境は、Windows10, Anaconda, Jupyter, GPU NVIDIA GeForce RTX 2060 です。
Contents
データセットの読み込み
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
''' 1. データの読み込みと前処理 ''' import os from torchvision import datasets import torchvision.transforms as transforms from torch.utils.data import DataLoader # ダウンロード先のディレクトリ root = './data' # トランスフォーマーオブジェクトを生成 transform = transforms.Compose( [transforms.ToTensor(), # Tensorオブジェクトに変換 transforms.Normalize((0.5), (0.5)) # 平均0.5、標準偏差0.5で正規化 ]) # 訓練用データの読み込み(60000セット) f_mnist_train = datasets.FashionMNIST( root=root, # データの保存先のディレクトリ download=True, # ダウンロードを許可 train=True, # 訓練データを指定 transform=transform) # トランスフォーマーオブジェクトを指定 # テスト用データの読み込み(10000セット) f_mnist_test = datasets.FashionMNIST( root=root, # データの保存先のディレクトリ download=True, # ダウンロードを許可 train=False, # テストデータを指定 transform=transform) # トランスフォーマーオブジェクトを指定 # ミニバッチのサイズ batch_size = 64 # 訓練用のデータローダー train_dataloader = DataLoader(f_mnist_train, # 訓練データ batch_size=batch_size, # ミニバッチのサイズ shuffle=True) # シャッフルして抽出 # テスト用のデータローダー test_dataloader = DataLoader(f_mnist_test, # テストデータ batch_size=batch_size, # ミニバッチのサイズ shuffle=False) # シャッフルして抽出 # データローダーが返すミニバッチの先頭データの形状を出力 for (x, t) in train_dataloader: # 訓練データ print(x.shape) print(t.shape) break for (x, t) in test_dataloader: # テストデータ print(x.shape) print(t.shape) break |
出力結果は以下のようになります。
|
1 2 3 4 |
torch.Size([64, 1, 28, 28]) torch.Size([64]) torch.Size([64, 1, 28, 28]) torch.Size([64]) |
データの形状が、NNではフラットにする必要がありましたが、CNNでは2階テンソルのままとなります。
モデルの定義
モデルの定義は以下のようになります。
畳込み層は「Conv2d()」メソッドを用います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
''' 2. モデルの定義 ''' import torch.nn as nn import torch.nn.functional as F class CNN(nn.Module): '''畳み込みニューラルネットワーク ''' def __init__(self): '''モデルの初期化を行う ''' # スーパークラスの__init__()を実行 super().__init__() # 畳み込み層1 self.conv1 = nn.Conv2d(in_channels=1, # 入力チャネル数 out_channels=32, # 出力チャネル数 kernel_size=3, # フィルターサイズ padding=(1,1), # パディングを行う padding_mode='zeros')# ゼロでパディング self.dropout1 = nn.Dropout2d(0.5) # 畳み込み層2 self.conv2 = nn.Conv2d(in_channels=32, # 入力チャネル数 out_channels=64, # 出力チャネル数 kernel_size=3, # フィルターサイズ padding=(1,1), # パディングを行う padding_mode='zeros')# ゼロでパディング self.dropout2 = nn.Dropout2d(0.5) # 全結合層1 self.fc1 = nn.Linear(in_features=28*28*64, # 入力はフラット化後のサイズ out_features=128) # ニューロン数 self.dropout3 = nn.Dropout(0.5) # 全結合層 self.fc2 = nn.Linear(in_features=128, # 入力のサイズは前層のニューロン数 out_features=10) # ニューロン数はクラス数と同数 def forward(self, x): '''MLPの順伝播処理を行う Parameters: x(ndarray(float32)):訓練データ、または検証データ Returns(float32): 出力層からの出力値 ''' x = torch.relu(self.conv1(x)) # 畳み込み層1の出力にReLUを適用 x = self.dropout1(x) # ドロップアウト1を適用 x = F.relu(self.conv2(x)) # 畳み込み層2の出力にReLUを適用 x = self.dropout2(x) # ドロップアウト2を適用 x = x.view(-1, 28 * 28 * 64) # (バッチサイズ, 28, 28, 64)を # (バッチサイズ, 50176)にフラット化 x = F.relu(self.fc1(x)) # 全結合層1の出力にReLUを適用 x = self.dropout3(x) # ドロップアウト3を適用 x = self.fc2(x) # 最終出力は活性化関数を適用しない return x |
ここでは定義だけなので、出力結果はありません。
モデルの生成
モデルの生成は以下のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 |
''' 3. モデルの生成 ''' import torch # 使用可能なデバイス(CPUまたはGPU)を取得する device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # モデルオブジェクトを生成し、使用可能なデバイスを設定する model = CNN().to(device) model # モデルの構造を出力 |
出力結果は以下のようになります。
|
1 2 3 4 5 6 7 8 9 |
CNN( (conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (dropout1): Dropout2d(p=0.5, inplace=False) (conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (dropout2): Dropout2d(p=0.5, inplace=False) (fc1): Linear(in_features=50176, out_features=128, bias=True) (dropout3): Dropout(p=0.5, inplace=False) (fc2): Linear(in_features=128, out_features=10, bias=True) ) |
2層の畳み込み層が配置されています。
損失関数とオプティマイザーの生成
|
1 2 3 4 5 6 7 8 9 |
''' 4. 損失関数とオプティマイザーの生成 ''' import torch.optim # クロスエントロピー誤差のオブジェクトを生成 criterion = nn.CrossEntropyLoss() # 勾配降下アルゴリズムを使用するオプティマイザーを生成 optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9) |
train_step()関数の定義
訓練データの学習用関数の定義を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
''' 5. train_step()関数の定義 ''' def train_step(x, t): '''バックプロパゲーションによるパラメーター更新を行う Parameters: x: 訓練データ t: 正解ラベル Returns: MLPの出力と正解ラベルのクロスエントロピー誤差 ''' model.train() # モデルを訓練(学習)モードにする preds = model(x) # モデルの出力を取得 loss = criterion(preds, t) # 出力と正解ラベルの誤差から損失を取得 optimizer.zero_grad() # 勾配を0で初期化(累積してしまうため) loss.backward() # 逆伝播の処理(自動微分による勾配計算) optimizer.step() # 勾配降下法の更新式を適用してバイアス、重みを更新 return loss, preds |
test_step()関数の定義
テストデータの検証用関数の定義を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
''' 6. test_step()関数の定義 ''' def test_step(x, t): '''テストデータを入力して損失と予測値を返す Parameters: x: テストデータ t: 正解ラベル Returns: MLPの出力と正解ラベルのクロスエントロピー誤差 ''' model.eval() # モデルを評価モードにする preds = model(x) # モデルの出力を取得 loss = criterion(preds, t) # 出力と正解ラベルの誤差から損失を取得 return loss, preds |
学習の早期終了判定用関数の定義
学習を早期に終わらせるかどうかを判定するための関数を定義します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
''' 7. 学習の進捗を監視し早期終了判定を行うクラス ''' class EarlyStopping: def __init__(self, patience=10, verbose=0): ''' Parameters: patience(int): 監視するエポック数(デフォルトは10) verbose(int): 早期終了の出力フラグ 出力(1),出力しない(0) ''' # インスタンス変数の初期化 # 監視中のエポック数のカウンターを初期化 self.epoch = 0 # 比較対象の損失を無限大'inf'で初期化 self.pre_loss = float('inf') # 監視対象のエポック数をパラメーターで初期化 self.patience = patience # 早期終了メッセージの出力フラグをパラメーターで初期化 self.verbose = verbose def __call__(self, current_loss): ''' Parameters: current_loss(float): 1エポック終了後の検証データの損失 Return: True:監視回数の上限までに前エポックの損失を超えた場合 False:監視回数の上限までに前エポックの損失を超えない場合 ''' # 前エポックの損失より大きくなった場合 if self.pre_loss < current_loss: self.epoch += 1 # カウンターを1増やす # 監視回数の上限に達した場合 if self.epoch > self.patience: if self.verbose: # 早期終了のフラグが1の場合 print('early stopping') # メッセージを出力 return True # 学習を終了するTrueを返す # 前エポックの損失以下の場合 else: self.epoch = 0 # カウンターを0に戻す self.pre_loss = current_loss # 損失の値を更新する # 監視回数の上限までに前エポックの損失を超えなければ # Falseを返して学習を続行する # 前エポックの損失を上回るが監視回数の範囲内であれば # Falseを返す必要があるので、return文の位置はここであることに注意 return False |
学習
実際に CNN で学習を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
%%time ''' 8.モデルを使用して学習する ''' from sklearn.metrics import accuracy_score # エポック数 epochs = 100 # 損失と精度の履歴を保存するためのdictオブジェクト history = {'loss':[],'accuracy':[], 'test_loss':[], 'test_accuracy':[]} # 早期終了の判定を行うオブジェクトを生成 ers = EarlyStopping(patience=5, # 監視対象回数 verbose=1) # 早期終了時にメッセージを出力 # 学習を行う for epoch in range(epochs): train_loss = 0. # 訓練1エポックあたりの損失を保持する変数 train_acc = 0. # 訓練1エポックごとの精度を保持する変数 test_loss = 0. # 評価1エポックごとの損失を保持する変数 test_acc = 0. # 評価1エポックごとの精度を保持する変数 # 1ステップにおける訓練用ミニバッチを使用した学習 for (x, t) in train_dataloader: # torch.Tensorオブジェクトにデバイスを割り当てる x, t = x.to(device), t.to(device) loss, preds = train_step(x, t) # 損失と予測値を取得 train_loss += loss.item() # ステップごとの損失を加算 train_acc += accuracy_score( t.tolist(), preds.argmax(dim=-1).tolist() ) # ステップごとの精度を加算 # 1ステップにおけるテストデータのミニバッチを使用した評価 for (x, t) in test_dataloader: # torch.Tensorオブジェクトにデバイスを割り当てる x, t = x.to(device), t.to(device) loss, preds = test_step(x, t) # 損失と予測値を取得 test_loss += loss.item() # ステップごとの損失を加算 test_acc += accuracy_score( t.tolist(), preds.argmax(dim=-1).tolist() ) # ステップごとの精度を加算 # 訓練時の損失の平均値を取得 avg_train_loss = train_loss / len(train_dataloader) # 訓練時の精度の平均値を取得 avg_train_acc = train_acc / len(train_dataloader) # 検証時の損失の平均値を取得 avg_test_loss = test_loss / len(test_dataloader) # 検証時の精度の平均値を取得 avg_test_acc = test_acc / len(test_dataloader) # 訓練データの履歴を保存する history['loss'].append(avg_train_loss) history['accuracy'].append(avg_train_acc) # テストデータの履歴を保存する history['test_loss'].append(avg_test_loss) history['test_accuracy'].append(avg_test_acc) # 1エポックごとに結果を出力 if (epoch + 1) % 1 == 0: print( 'epoch({}) train_loss: {:.4} train_acc: {:.4} val_loss: {:.4} val_acc: {:.4}'.format( epoch+1, avg_train_loss, # 訓練データの損失を出力 avg_train_acc, # 訓練データの精度を出力 avg_test_loss, # テストデータの損失を出力 avg_test_acc # テストデータの精度を出力 )) # 検証データの損失をEarlyStoppingオブジェクトに渡して早期終了を判定 if ers(avg_test_loss): # 監視対象のエポックで損失が改善されなければ学習を終了 break |
実行時間は、約15分でした。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
epoch(1) train_loss: 0.8973 train_acc: 0.6822 val_loss: 0.5532 val_acc: 0.7943 epoch(2) train_loss: 0.6024 train_acc: 0.784 val_loss: 0.4713 val_acc: 0.8303 epoch(3) train_loss: 0.5312 train_acc: 0.8112 val_loss: 0.442 val_acc: 0.8404 epoch(4) train_loss: 0.4864 train_acc: 0.8282 val_loss: 0.415 val_acc: 0.8514 epoch(5) train_loss: 0.4575 train_acc: 0.8372 val_loss: 0.3906 val_acc: 0.8575 epoch(6) train_loss: 0.4344 train_acc: 0.846 val_loss: 0.3773 val_acc: 0.8642 epoch(7) train_loss: 0.4172 train_acc: 0.8512 val_loss: 0.3673 val_acc: 0.8685 epoch(8) train_loss: 0.4022 train_acc: 0.8571 val_loss: 0.36 val_acc: 0.8665 epoch(9) train_loss: 0.3885 train_acc: 0.8608 val_loss: 0.3449 val_acc: 0.8723 epoch(10) train_loss: 0.3768 train_acc: 0.8669 val_loss: 0.334 val_acc: 0.876 epoch(11) train_loss: 0.3682 train_acc: 0.8689 val_loss: 0.3279 val_acc: 0.8792 epoch(12) train_loss: 0.3599 train_acc: 0.8735 val_loss: 0.3227 val_acc: 0.8829 epoch(13) train_loss: 0.3506 train_acc: 0.8753 val_loss: 0.3159 val_acc: 0.8835 epoch(14) train_loss: 0.3425 train_acc: 0.8768 val_loss: 0.3133 val_acc: 0.884 epoch(15) train_loss: 0.334 train_acc: 0.8807 val_loss: 0.3063 val_acc: 0.8854 epoch(16) train_loss: 0.3298 train_acc: 0.8808 val_loss: 0.3 val_acc: 0.888 epoch(17) train_loss: 0.3231 train_acc: 0.8821 val_loss: 0.2958 val_acc: 0.89 epoch(18) train_loss: 0.3183 train_acc: 0.8833 val_loss: 0.2961 val_acc: 0.89 epoch(19) train_loss: 0.3125 train_acc: 0.8872 val_loss: 0.2895 val_acc: 0.8925 epoch(20) train_loss: 0.3071 train_acc: 0.8891 val_loss: 0.2911 val_acc: 0.894 epoch(21) train_loss: 0.3031 train_acc: 0.89 val_loss: 0.2855 val_acc: 0.8934 epoch(22) train_loss: 0.2955 train_acc: 0.8928 val_loss: 0.2839 val_acc: 0.8973 epoch(23) train_loss: 0.2943 train_acc: 0.8938 val_loss: 0.2779 val_acc: 0.8986 epoch(24) train_loss: 0.288 train_acc: 0.8951 val_loss: 0.2809 val_acc: 0.8967 epoch(25) train_loss: 0.2864 train_acc: 0.8949 val_loss: 0.2748 val_acc: 0.8991 epoch(26) train_loss: 0.2796 train_acc: 0.898 val_loss: 0.2731 val_acc: 0.9009 epoch(27) train_loss: 0.278 train_acc: 0.8991 val_loss: 0.2729 val_acc: 0.8988 epoch(28) train_loss: 0.2733 train_acc: 0.9004 val_loss: 0.2685 val_acc: 0.9012 epoch(29) train_loss: 0.2699 train_acc: 0.9014 val_loss: 0.2734 val_acc: 0.9003 epoch(30) train_loss: 0.2648 train_acc: 0.9035 val_loss: 0.2669 val_acc: 0.9018 epoch(31) train_loss: 0.2612 train_acc: 0.9046 val_loss: 0.2608 val_acc: 0.9039 epoch(32) train_loss: 0.2562 train_acc: 0.9049 val_loss: 0.2641 val_acc: 0.9037 epoch(33) train_loss: 0.2532 train_acc: 0.9065 val_loss: 0.2607 val_acc: 0.9044 epoch(34) train_loss: 0.2534 train_acc: 0.9075 val_loss: 0.2622 val_acc: 0.9029 epoch(35) train_loss: 0.2506 train_acc: 0.9084 val_loss: 0.2606 val_acc: 0.9048 epoch(36) train_loss: 0.2445 train_acc: 0.9095 val_loss: 0.2575 val_acc: 0.907 epoch(37) train_loss: 0.2453 train_acc: 0.9085 val_loss: 0.2573 val_acc: 0.9061 epoch(38) train_loss: 0.2399 train_acc: 0.9112 val_loss: 0.2581 val_acc: 0.9073 epoch(39) train_loss: 0.2361 train_acc: 0.9125 val_loss: 0.2558 val_acc: 0.9085 epoch(40) train_loss: 0.2348 train_acc: 0.9131 val_loss: 0.2539 val_acc: 0.9085 epoch(41) train_loss: 0.2315 train_acc: 0.9146 val_loss: 0.2582 val_acc: 0.9062 epoch(42) train_loss: 0.2289 train_acc: 0.9144 val_loss: 0.2547 val_acc: 0.9084 epoch(43) train_loss: 0.227 train_acc: 0.9153 val_loss: 0.2539 val_acc: 0.9096 epoch(44) train_loss: 0.2254 train_acc: 0.9158 val_loss: 0.2511 val_acc: 0.9091 epoch(45) train_loss: 0.2212 train_acc: 0.9189 val_loss: 0.2534 val_acc: 0.9079 epoch(46) train_loss: 0.2186 train_acc: 0.9187 val_loss: 0.2547 val_acc: 0.9094 epoch(47) train_loss: 0.216 train_acc: 0.9201 val_loss: 0.2504 val_acc: 0.9095 epoch(48) train_loss: 0.2131 train_acc: 0.9211 val_loss: 0.2488 val_acc: 0.9115 epoch(49) train_loss: 0.2134 train_acc: 0.9207 val_loss: 0.2491 val_acc: 0.9121 epoch(50) train_loss: 0.2095 train_acc: 0.9202 val_loss: 0.2487 val_acc: 0.913 epoch(51) train_loss: 0.2038 train_acc: 0.9236 val_loss: 0.2484 val_acc: 0.9113 epoch(52) train_loss: 0.2036 train_acc: 0.9242 val_loss: 0.2484 val_acc: 0.9103 epoch(53) train_loss: 0.2035 train_acc: 0.9233 val_loss: 0.2476 val_acc: 0.9134 epoch(54) train_loss: 0.2015 train_acc: 0.9248 val_loss: 0.2501 val_acc: 0.9105 epoch(55) train_loss: 0.2004 train_acc: 0.9249 val_loss: 0.2492 val_acc: 0.9135 epoch(56) train_loss: 0.1952 train_acc: 0.9261 val_loss: 0.2469 val_acc: 0.9147 epoch(57) train_loss: 0.1933 train_acc: 0.9272 val_loss: 0.2478 val_acc: 0.9113 epoch(58) train_loss: 0.1886 train_acc: 0.9289 val_loss: 0.2514 val_acc: 0.9102 epoch(59) train_loss: 0.1915 train_acc: 0.9287 val_loss: 0.25 val_acc: 0.914 epoch(60) train_loss: 0.1866 train_acc: 0.9299 val_loss: 0.2416 val_acc: 0.9148 epoch(61) train_loss: 0.1859 train_acc: 0.9311 val_loss: 0.2453 val_acc: 0.9121 epoch(62) train_loss: 0.1839 train_acc: 0.9317 val_loss: 0.2436 val_acc: 0.9131 epoch(63) train_loss: 0.1807 train_acc: 0.9319 val_loss: 0.2493 val_acc: 0.9145 epoch(64) train_loss: 0.1793 train_acc: 0.9322 val_loss: 0.244 val_acc: 0.9165 epoch(65) train_loss: 0.1773 train_acc: 0.9336 val_loss: 0.2425 val_acc: 0.9164 epoch(66) train_loss: 0.1759 train_acc: 0.9335 val_loss: 0.2464 val_acc: 0.9157 early stopping Wall time: 15min 21s |
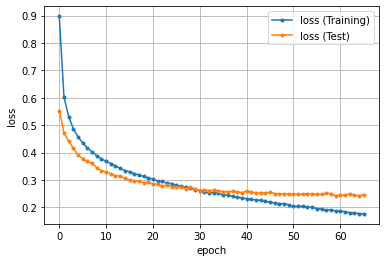
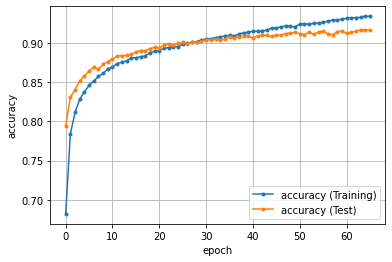
精度のグラフ化
エポックごとの損失と精度(正解率)をグラフ化します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
''' 9. 損失と精度の推移をグラフにする ''' import matplotlib.pyplot as plt %matplotlib inline # 損失 plt.plot(history['loss'], marker='.', label='loss (Training)') plt.plot(history['test_loss'], marker='.', label='loss (Test)') plt.legend(loc='best') plt.grid() plt.xlabel('epoch') plt.ylabel('loss') plt.show() # 精度 plt.plot(history['accuracy'], marker='.', label='accuracy (Training)') plt.plot(history['test_accuracy'], marker='.', label='accuracy (Test)') plt.legend(loc='best') plt.grid() plt.xlabel('epoch') plt.ylabel('accuracy') plt.show() |
参考文献
関連記事
-

-
【機械学習・手法比較】決定木とナイーブベイズを比較してみた。
同じデータを使って、教師有り機械学習手法の 決定木(Decision Tree)とナイーブベイズ(N
-

-
【Chainer】手書き数字認識をしてみた【Deep Learning】
Chainerを用いて、ニューラルネットワークを構築し、手書き数字認識を行ったときのメモです。
-
-
【深層学習】 TensorFlow と Keras をインストールする【Python】
今回は、Google Colaboratory 上で、深層学習(DeepLearning)フレームワ
-
-
【機械学習】パーセプトロン(Perceptron)について。
パーセプトロンは、教師あり学習の中でも、入出力モデルベース(eager learning:働き者の学
-
-
【機械学習】モンテカルロ法(Monte Carlo method)について。
モンテカルロ法(Monte Carlo method)とは、シュミレーションや数値計算を乱数を用いて
-
-
【Weka】CSVファイルを読み込んで決定木を実行。
フリーの機械学習ソフト Weka を使って、CSVファイルを読み込んで決定木(Decision Tr
-
-
【Weka】アソシエーション・ルール(association rule)【機械学習】
フリーの機械学習ツール Weka でアソシエーション・ルール(association rule)を使
-
-
【TensorFlow】GPUを認識しない時の対処方法【Python】
TensorFlow で GPU を認識させようとしたときにハマってしまったので、その対処方法のメモ
-
-
【Weka】欠損データを自動的に補完するフィルタを使ってみた。
機械学習で用いるデータについてです。データは完璧なことに越したことはないが、通常は、ある属性の値が入
-
-
【PyTorch】GPUのメモリ不足でエラーになったときの対処方法。
PyTorch で深層学習していて、 GPUのメモリ不足でエラーが出てしまったので、対処方法のメモで



















