【機械学習・手法比較】決定木とナイーブベイズを比較してみた。
同じデータを使って、教師有り機械学習手法の 決定木(Decision Tree)とナイーブベイズ(Naive Bayes)を比較してみました。
機械学習用のフリーソフト「Weka」を用いて検証しました。
Contents
データ準備
今回用いたデータは以下のようなもので、条件によってテニスをプレイするかどうかを学習によって判断します。
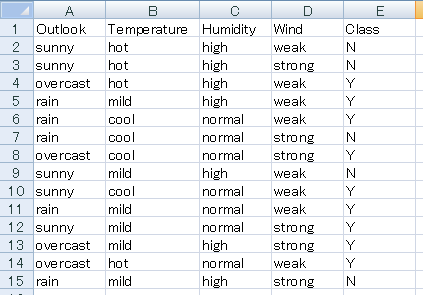
Class 列が「Y」ならテニスをプレイし、「N」ならプレイしないことを表しています。
決定木(Decision Tree)
まず、決定木で検証します。
Weka の分類器選択で、「trees」->「J48」を選択します。
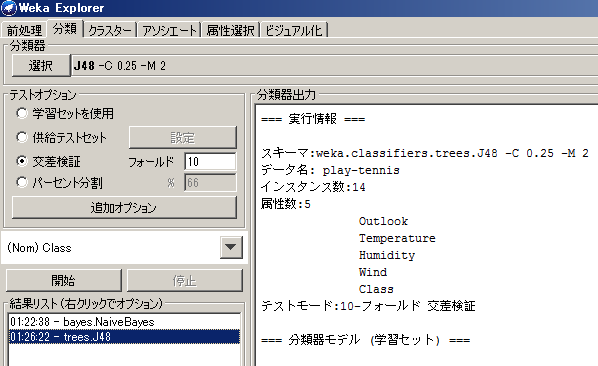
分類器出力結果は以下のとおりです。
=== 実行情報 ===
スキーマ:weka.classifiers.trees.J48 -C 0.25 -M 2
データ名: play-tennis
インスタンス数:14
属性数:5
Outlook
Temperature
Humidity
Wind
Class
テストモード:10-フォールド 交差検証=== 分類器モデル (学習セット) ===
J48 pruned tree
——————Outlook = sunny
| Humidity = high: N (3.0)
| Humidity = normal: Y (2.0)
Outlook = overcast: Y (4.0)
Outlook = rain
| Wind = weak: Y (3.0)
| Wind = strong: N (2.0)Number of Leaves : 5
Size of the tree : 8
モデルビルド所要時間: 0.01 秒
=== 階層化交差検証 ===
=== Summary ===Correctly Classified Instances 7 50 %
Incorrectly Classified Instances 7 50 %
Kappa statistic -0.0426
Mean absolute error 0.4167
Root mean squared error 0.5984
Relative absolute error 87.5 %
Root relative squared error 121.2987 %
Total Number of Instances 14=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure ROC Area Class
0.4 0.444 0.333 0.4 0.364 0.633 N
0.556 0.6 0.625 0.556 0.588 0.633 Y
Weighted Avg. 0.5 0.544 0.521 0.5 0.508 0.633=== Confusion Matrix ===
a b <– classified as
2 3 | a = N
4 5 | b = Y
Precision(適合率、正確性)が約54%、Recall(再現率、網羅性)が約50%となっています。あまり、良い結果ではありませんね。
ちなみに、分類器の木構造は以下のようになりました。

この木構造を見ると、最初に属性「Outlook」で分類するのが、一番情報が整理され、エントロピーが小さくなることなどが分かったりします。
ナイーブベイズ(Naive Bayes)
次に、ナイーブベイズで検証してみました。
Weka の分類器選択で、「bayes」->「NaiveBayes」を選択します。
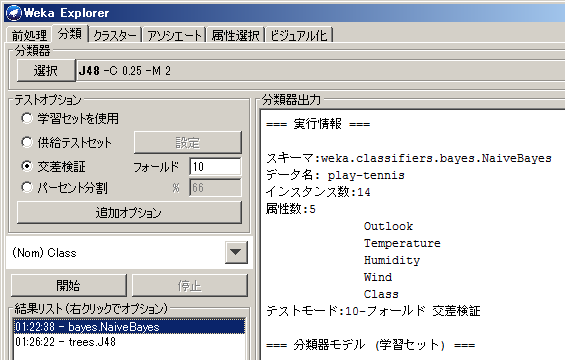
分類器出力結果は以下のとおりです。
=== 実行情報 ===
スキーマ:weka.classifiers.bayes.NaiveBayes
データ名: play-tennis
インスタンス数:14
属性数:5
Outlook
Temperature
Humidity
Wind
Class
テストモード:10-フォールド 交差検証=== 分類器モデル (学習セット) ===
Naive Bayes Classifier
Class
Attribute N Y
(0.38) (0.63)
=============================
Outlook
sunny 4.0 3.0
overcast 1.0 5.0
rain 3.0 4.0
[total] 8.0 12.0Temperature
hot 3.0 3.0
mild 3.0 5.0
cool 2.0 4.0
[total] 8.0 12.0Humidity
high 5.0 4.0
normal 2.0 7.0
[total] 7.0 11.0Wind
weak 3.0 7.0
strong 4.0 4.0
[total] 7.0 11.0
モデルビルド所要時間: 0 秒
=== 階層化交差検証 ===
=== Summary ===Correctly Classified Instances 8 57.1429 %
Incorrectly Classified Instances 6 42.8571 %
Kappa statistic -0.0244
Mean absolute error 0.4374
Root mean squared error 0.4916
Relative absolute error 91.8631 %
Root relative squared error 99.6492 %
Total Number of Instances 14=== Detailed Accuracy By Class ===
TP Rate FP Rate Precision Recall F-Measure ROC Area Class
0.2 0.222 0.333 0.2 0.25 0.578 N
0.778 0.8 0.636 0.778 0.7 0.578 Y
Weighted Avg. 0.571 0.594 0.528 0.571 0.539 0.578=== Confusion Matrix ===
a b <– classified as
1 4 | a = N
2 7 | b = Y
Precision(適合率、正確性)が約53%、Recall(再現率、網羅性)が約57%となっています。
決定木と比べて、ちょっとだけ精度が高くなっていることが分かります。
以上が決定木とナイーブベイズの比較でした。
関連記事
-

-
【機械学習】パーセプトロン(Perceptron)について。
パーセプトロンは、教師あり学習の中でも、入出力モデルベース(eager learning:働き者の学
-
-
【機械学習】モンテカルロ法(Monte Carlo method)について。
モンテカルロ法(Monte Carlo method)とは、シュミレーションや数値計算を乱数を用いて
-
-
【画像認識】 Google画像検索結果を取得する方法 【google image download】
今回は、深層学習(DeepLearning)で画像認識をするための画像データの収集を、Google画
-

-
【Weka】アソシエーション・ルール(association rule)【機械学習】
フリーの機械学習ツール Weka でアソシエーション・ルール(association rule)を使
-
-
【PyTorch】GPUのメモリ不足でエラーになったときの対処方法。
PyTorch で深層学習していて、 GPUのメモリ不足でエラーが出てしまったので、対処方法のメモで
-
-
【TensorFlow】GPUを認識しない時の対処方法【Python】
TensorFlow で GPU を認識させようとしたときにハマってしまったので、その対処方法のメモ
-
-
【Fashion-MNIST】ファッションアイテムのデータセットを使ってみた【TensorFlow】
今回は、機械学習用に公開されているデータセットの1つである「Fashion-MNIST」について紹介
-
-
【機械学習】 scikit-learn で不正解データを抽出する方法【Python】
Python の scikit-learn ライブラリを使って機械学習でテストデータを識別(2クラス
-
-
【機械学習】 scikit-learn で精度・再現率・F値を算出する方法【Python】
今回は、2クラス分類で Python の scikit-learn を使った評価指標である、精度(P
-
-
【Weka】ARFF 形式から CSV 形式に簡単に変換する方法。
フリーのデータマイニングツールである WEKA では、ARFF 形式と CSV 形式のデータを読み込



















