【Weka】アソシエーション・ルール(association rule)【機械学習】
公開日:
:
最終更新日:2018/07/26
機械学習 association rule, Weka, アソシエーション・ルール, 信頼度, 支持度
フリーの機械学習ツール Weka でアソシエーション・ルール(association rule)を使ってみたときのメモです。
アソシエーション・ルール(association rule)とは、事象間の共起性(Co-occurence)を表す規則(rule)を意味します。
有名なのは、大量のスーパーの購入履歴から「ビールとおむつが同時に買われることが多い」というようなルールを探し出すことです。
Contents
データの準備
まず、CSV 形式で以下のようなデータを用意しました。

7つの事象の共起性のルールを自動的に見つけていきます。ちなみに、「yes」となっているところが対象事象が観測されたことを意味しています。
データの読み込みは、Weka を起動させ、
前処理 -> ファイルを開く からCSV ファイルを選択します。
最小支持度(minsup)と最小信頼度(minconf)の設定
膨大な数のアソシエーション・ルールから有用なルールと無用なルールの区別を行うための指標が、支持度(support)と信頼度(confidence)になります。
大量のルールから、ある条件を満たすルールのみを有用なルールとみなし抽出します。
その際に用いる、最小支持度(minsup)と最小信頼度(minconf)を Weka で設定します。
アソシエートタブの「選択」ボタンの横のエリアをクリックします。

すると、以下のようなウィンドウが開きます。
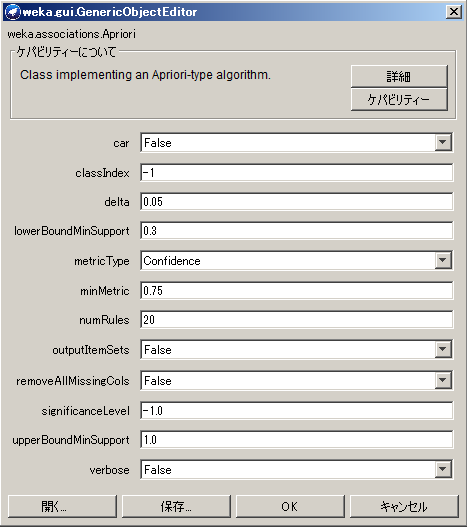
最小支持度が「lower BoundMinSupport」で設定でき、最小信頼度が「minMetric」で設定できます。
今回は、最小支持度が 30%、最小信頼度が 75% で設定しました。
実行および結果
「開始」ボタンを押すと、ルールの抽出が行われ、右側に結果が表示されます。
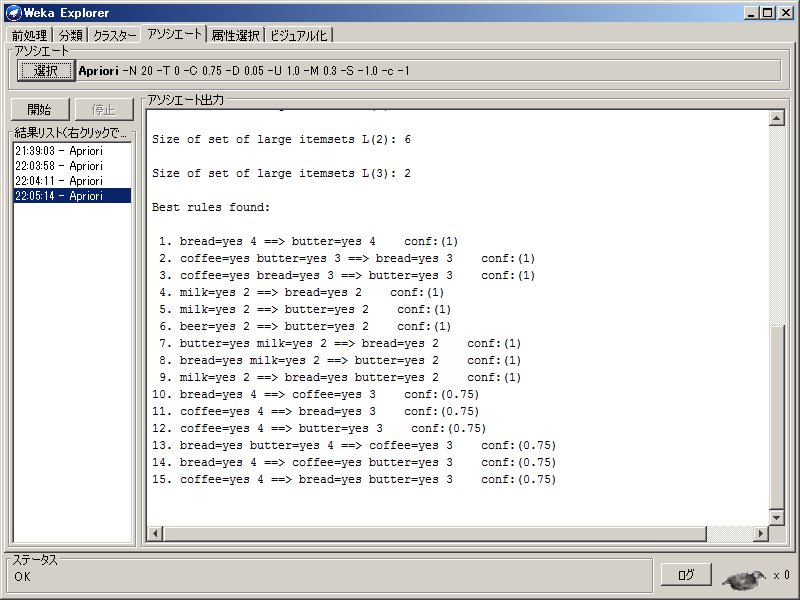
結果は以下のようになり、条件を満たす15個のルールが抽出されました。
ちなみに「conf」は信頼度を表しています。
=== 実行情報 ===
スキーマ: weka.associations.Apriori -N 20 -T 0 -C 0.75 -D 0.05 -U 1.0 -M 0.3 -S -1.0 -c -1
関連: association_rule_data
インスタンス: 8
要素: 7
coffee
bread
butter
milk
beer
beans
rice
=== アソシエートモデル (トレーニングセット) ===
Apriori
=======Minimum support: 0.3 (2 instances)
Minimum metric <confidence>: 0.75
Number of cycles performed: 14Generated sets of large itemsets:
Size of set of large itemsets L(1): 6
Size of set of large itemsets L(2): 6
Size of set of large itemsets L(3): 2
Best rules found:
1. bread=yes 4 ==> butter=yes 4 conf:(1)
2. coffee=yes butter=yes 3 ==> bread=yes 3 conf:(1)
3. coffee=yes bread=yes 3 ==> butter=yes 3 conf:(1)
4. milk=yes 2 ==> bread=yes 2 conf:(1)
5. milk=yes 2 ==> butter=yes 2 conf:(1)
6. beer=yes 2 ==> butter=yes 2 conf:(1)
7. butter=yes milk=yes 2 ==> bread=yes 2 conf:(1)
8. bread=yes milk=yes 2 ==> butter=yes 2 conf:(1)
9. milk=yes 2 ==> bread=yes butter=yes 2 conf:(1)
10. bread=yes 4 ==> coffee=yes 3 conf:(0.75)
11. coffee=yes 4 ==> bread=yes 3 conf:(0.75)
12. coffee=yes 4 ==> butter=yes 3 conf:(0.75)
13. bread=yes butter=yes 4 ==> coffee=yes 3 conf:(0.75)
14. bread=yes 4 ==> coffee=yes butter=yes 3 conf:(0.75)
15. coffee=yes 4 ==> bread=yes butter=yes 3 conf:(0.75)
関連記事
-

-
【転移学習】学習済みVGG16 による転移学習を行う方法【PyTorch】
今回は、PyTorch を使って、学習済みのモデル VGG16 を用いて転移学習をしてみました。
-
-
【PyTorch】畳込みニューラルネットワークを構築する方法【CNN】
今回は、PyTorch を使って畳込みニューラルネットワーク(CNN)を構築する方法について紹介しま
-

-
【Weka】欠損データを自動的に補完するフィルタを使ってみた。
機械学習で用いるデータについてです。データは完璧なことに越したことはないが、通常は、ある属性の値が入
-
-
【Weka】CSVファイルを読み込んで決定木を実行。
フリーの機械学習ソフト Weka を使って、CSVファイルを読み込んで決定木(Decision Tr
-
-
【Weka】ARFF 形式から CSV 形式に簡単に変換する方法。
フリーのデータマイニングツールである WEKA では、ARFF 形式と CSV 形式のデータを読み込
-
-
【機械学習】モンテカルロ法(Monte Carlo method)について。
モンテカルロ法(Monte Carlo method)とは、シュミレーションや数値計算を乱数を用いて
-
-
【Chainer】手書き数字認識をしてみた【Deep Learning】
Chainerを用いて、ニューラルネットワークを構築し、手書き数字認識を行ったときのメモです。
-
-
【TensorFlow】GPUを認識しない時の対処方法【Python】
TensorFlow で GPU を認識させようとしたときにハマってしまったので、その対処方法のメモ
-
-
機械学習の手法のまとめ。
機械学習は、「与えられた入出力事例をモデル化する行為」のことで、ディープラーニングなどで注目を集めて
-
-
【機械学習・手法比較】決定木とナイーブベイズを比較してみた。
同じデータを使って、教師有り機械学習手法の 決定木(Decision Tree)とナイーブベイズ(N



















