【Python】NLTK(自然言語処理ライブラリ)を使ってみた。
Python の自然言語処理ライブラリである NLTK を Linux 環境にインストールして使ってみたときのメモです。
NLTK をインストール
以下のコマンドでインストールします。
|
1 |
$ sudo python3 -m pip install -U nltk |
サンプルテキストデータをダウンロード
NLTK ではサンプル用のテキストデータが用意されていて、以下のコマンドで使用できる。
|
1 2 3 4 |
$ python3 >>> import nltk >>> nltk.download() |
「d」を入力し、「book」を入力すると、テキストの集合がダウンロードできる。
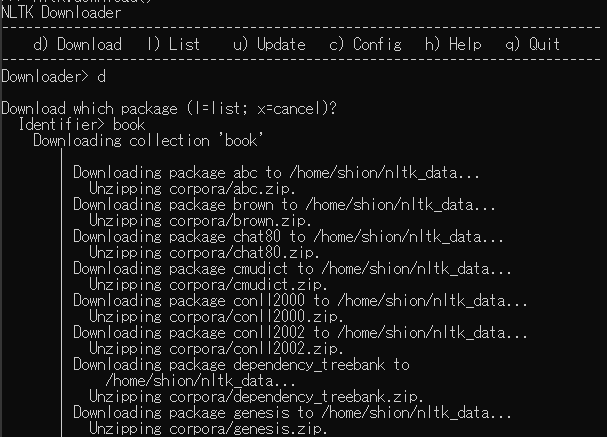
以下のコードを使って、ダウンロードしたテキストに簡単にアクセスできます。
|
1 |
>>> from nltk.book import * |

「text1」にアクセスしたいときは、以下のようにします。
|
1 |
>>> text1 |
<Text: Moby Dick by Herman Melville 1851>
関連記事
-

-
【Python】形態素解析器 Mecab を Linux(Ubuntu)で使ってみた。
Linux の Ubuntu OS に、形態素解析器 Mecab をインストールし、使ってみたときの
-
-
【テキストマイニング】 bigram を用いて小説の書き手の識別をしてみる
「テキストマイニング入門」という本に書かれている内容に添って RMeCab を使った小説の分析を行っ
-
-
【mecab-python3】parseToNode で surface が正しく取得できないときの対処法。
python3 で mecab-python3 を使うと、parseToNode で surface