【機械学習】 scikit-learn で不正解データを抽出する方法【Python】
Python の scikit-learn ライブラリを使って機械学習でテストデータを識別(2クラス分類)をしたときに、正解・不正解データを抽出する方法について紹介します。
scikit-learn で正解率を出したいのであれば、混合行列(confusion matrix)を出力すれば良いのですが、これだと正解・不正解データの数しか出力されません。
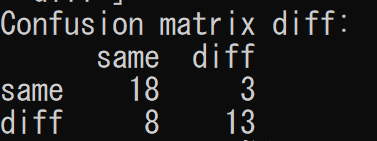
これだと、不正解データ(正しく識別できなかったデータ)にはどのような傾向があるかなどの分析ができないため、正解・不正解データを抽出したいなぁと思って調べてみました。
Contents
classifier.predict について
scikit-learn の「classifier.predict」関数にテストデータを与えると、識別結果(学習した識別器が判断したラベルデータ)がリストで返ってきます。
今回は「classifier.fit」関数で学習データを用いて既に学習済みの場合を想定しています。
|
1 |
py = classifier.predict( test_data_df ) |
2クラス分類でラベル「same」「diff」の場合の結果が以下のようになります。
|
1 2 3 4 5 |
['same' 'same' 'diff' 'diff' 'diff' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'diff' 'diff' 'diff' 'same' 'same' 'diff' 'diff' 'same' 'diff' 'same' 'same' 'diff' 'diff' 'same' 'diff' 'diff' 'same' 'diff' 'same' 'diff' 'diff'] |
これが、与えた全てのテストデータの識別結果となります。
テストデータのうち、正解ラベルが same のものを抽出して識別した結果を抽出したい場合は、以下のようにします。
|
1 |
py = classifier.predict( test_data_df [labels_test_data=='same'] ) |
labels_test_data は、テストデータのラベル(正解ラベル「same」or「diff」が並んだもの)となります。
|
1 2 3 4 |
テストデータのうち、正解ラベルが same のものを抽出して識別 ['same' 'same' 'diff' 'diff' 'diff' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same' 'same'] |
一方、テストデータのうち、正解ラベルが diff のものを抽出して識別した結果を抽出したい場合は、以下のようにします。
|
1 |
py = classifier.predict(features_diff_test[labels_diff_test=='diff']) |
|
1 2 3 4 |
テストデータのうち、正解ラベルが diff のものを抽出して識別 ['diff' 'diff' 'diff' 'same' 'same' 'diff' 'diff' 'same' 'diff' 'same' 'same' 'diff' 'diff' 'same' 'diff' 'diff' 'same' 'diff' 'same' 'diff' 'diff'] |
numpy.where を使う
whrere は Numpy ライブラリの関数で、条件を満たす要素の位置(インデックス)を返してくれます。
先ほど抽出した、正解ラベルが same のものと、diff のものを利用します。
例えば「正解ラベルが same のうち、識別結果が diff のもの」を不正解データと扱うことができます。
コードで書くと以下のようになります。
|
1 2 3 4 |
# テストデータのうち、正解ラベルが same のものを抽出して識別 py = classifier.predict( test_data_df [labels_test_data=='same'] ) # 識別結果が diff のもの print(np.where(py=='diff')) |
|
1 |
(array([ 2, 3, 5, 9, 13, 17, 20]),) |
リストの要素の位置(インデックス)が返ってくることが分かります。
不正解データの抽出
以上を踏まえて、不正解データ(識別器が誤って識別してしまったデータ)の抽出を行います。
不正解データのパターンとしては、予測した結果のうち、
- 正解ラベルが same のうち、識別結果が diff と誤って判断してしまった(False Negative; FN)。
- 正解ラベルが diff のうち、識別結果が same と誤って判断してしまった(False Positive; FP)。
の2パターンが考えられます。
where で抽出した リストの要素の位置 を iloc で与えて行番号から抽出を行います。
iloc は、pandas で行番号・列番号を指定して抽出を行う関数です。
●False Negative; FN
|
1 2 3 4 |
# テストデータのうち、正解ラベルが same のものを抽出して識別 py = classifier.predict( test_data_df [labels_test_data=='same'] ) tmp_df = df_2_class_test[labels_test=='same'].iloc[np.where(py=='diff')] print(tmp_df[['q_user_id', 'r_user_id']]) |
df_2_class_test は元の(学習に使用した特徴量なども含めた)データです。
●False Positive; FP
|
1 2 3 4 |
# テストデータのうち、正解ラベルが diff のものを抽出して識別 py = classifier.predict( test_data_df [labels_test_data=='diff'] ) tmp_df = df_2_class_test[labels_test=='diff'].iloc[np.where(py=='same')] print(tmp_df[['q_user_id', 'r_user_id']]) |
正解データの抽出
正解データのパターンとしては、予測した結果のうち、
- 正解ラベルが same のうち、識別結果が same と正しく判断した(True Positive; TP)。
- 正解ラベルが diff のうち、識別結果が diff と正しく判断した(True Negative; TN)。
の2パターンが考えられます。
●True Positive; TP
|
1 2 3 4 |
# テストデータのうち、正解ラベルが same のものを抽出して識別 py = classifier.predict( test_data_df [labels_test_data=='same'] ) tmp_df = df_2_class_test[labels_test=='same'].iloc[np.where(py=='same')] print(tmp_df[['q_user_id', 'r_user_id']]) |
●True Negative; TN
|
1 2 3 4 |
# テストデータのうち、正解ラベルが diff のものを抽出して識別 py = classifier.predict( test_data_df [labels_test_data=='diff'] ) tmp_df = df_2_class_test[labels_test=='diff'].iloc[np.where(py=='diff')] print(tmp_df[['q_user_id', 'r_user_id']]) |
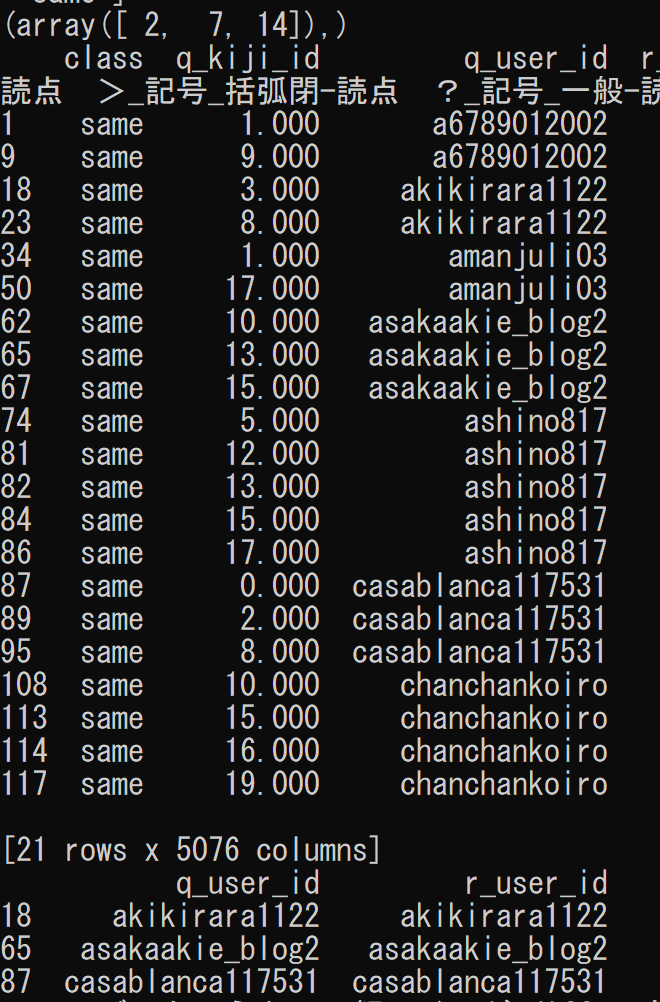
抽出結果
結果が以下のように出力され、それぞれに該当する行と列だけ抽出されていることが確認できます。
関連記事
-

-
【機械学習】パーセプトロン(Perceptron)について。
パーセプトロンは、教師あり学習の中でも、入出力モデルベース(eager learning:働き者の学
-
-
【PyTorch】畳込みニューラルネットワークを構築する方法【CNN】
今回は、PyTorch を使って畳込みニューラルネットワーク(CNN)を構築する方法について紹介しま
-
-
【PyTorch】ニューラルネットワークを構築する方法【NN】
今回は、PyTorch を使って、ニューラルネットワーク(NN)を構築したときのメモです。 フ
-
-
【深層学習】 TensorFlow と Keras をインストールする【Python】
今回は、Google Colaboratory 上で、深層学習(DeepLearning)フレームワ
-
-
【探索】縦型・横型・反復深化法の探索手法の比較。
探索とは、チェスや将棋や囲碁などのゲームをコンピュータがプレイするときに、どの手を指すかを決定するの
-
-
【画像認識】 Google画像検索結果を取得する方法 【google image download】
今回は、深層学習(DeepLearning)で画像認識をするための画像データの収集を、Google画
-
-
【転移学習】学習済みVGG16 による転移学習を行う方法【PyTorch】
今回は、PyTorch を使って、学習済みのモデル VGG16 を用いて転移学習をしてみました。
-
-
【Chainer】手書き数字認識をしてみた【Deep Learning】
Chainerを用いて、ニューラルネットワークを構築し、手書き数字認識を行ったときのメモです。
-

-
【Weka】アソシエーション・ルール(association rule)【機械学習】
フリーの機械学習ツール Weka でアソシエーション・ルール(association rule)を使
-
-
【機械学習】 scikit-learn で精度・再現率・F値を算出する方法【Python】
今回は、2クラス分類で Python の scikit-learn を使った評価指標である、精度(P